PySpark
PySpark实战
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
Sprk作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。PySpark是Spark的Python API,可以让Python开发者快速的进行Spark的开发。
基础准备
构建PySpark执行环境入口对象
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
PySpark的执行环境入口对象是: 类SparkContext的类对象
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName('test_spark_app')
sc = SparkContext(conf=conf)
print(sc.version)
sc.stop()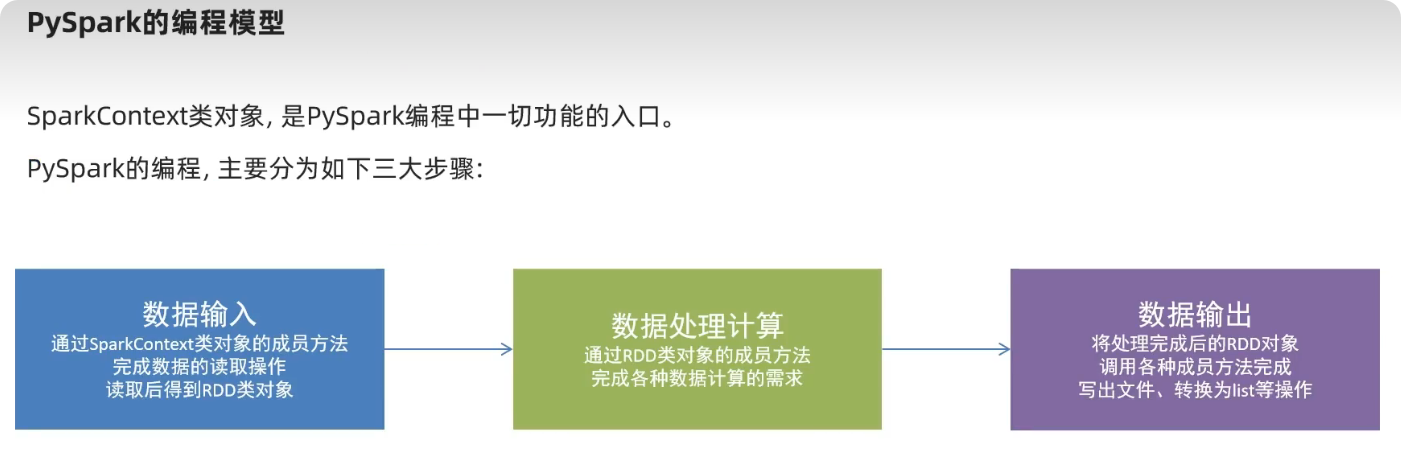
流程:
- 通过sparkContext对象 - > 构建RDD - > RDD操作 - > 输出结果
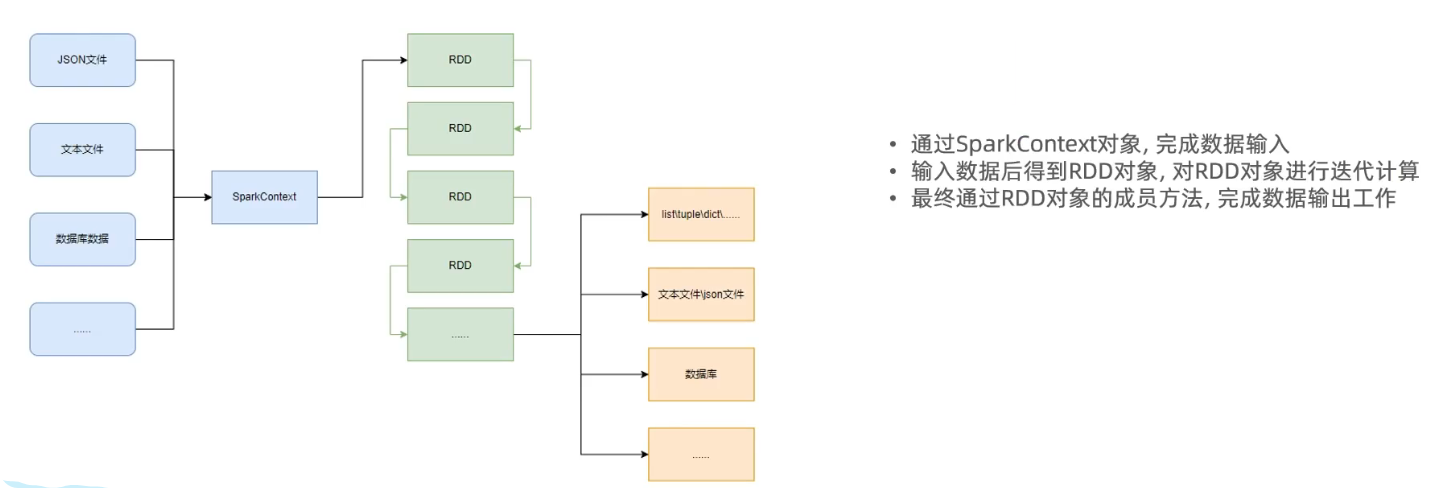
数据输入(得到RDD对象)
PySpark支持多种数据的输入,在输入完成后,都会得到一个:
RDD类的对象 - > 该对象包含了数据集的元数据和数据。
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
- RDD对象是什么?为什么要使用它? RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,它可以:
INFO
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是
RDD(RDD迭代计算)后续对数据进行各类计算,都是基于RDD对象进行
- 如何输入数据到Spark(即得到RDD对象)
INFO
- 通过
SparkContext的parallelize成员方法,将Python数据容器转换为RDD对象 - 通过
SparkContext的textFile成员方法,读取文本文件得到RDD对象
- 通过
from pyspark import SparkConf, SparkContext
# 创建SparkConf对象
conf = SparkConf().setAppName("test_spark").setMaster("local")
# 创建SparkContext对象
sc = SparkContext(conf=conf)
# 创建RDD
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((10, 20, 30, 40, 50))
rdd3 = sc.parallelize('hello world')
rdd4 = sc.parallelize({'a': 1, 'b': 2, 'c': 3})
rdd5 = sc.parallelize({1, 2, 3, 4, 5})
# 查看里面的数据
# print(rdd1.collect())
rdd6 = sc.textFile('input.txt')
print(rdd6.collect())TIP
大概就好比给数据封装成list,使得它有更多的处理数据的方法。
数据处理(RDD操作)
map
map算子
是将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数中),返回新的RDD
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = 'D:\python\python.exe'
# 创建SparkConf对象
conf = SparkConf().setAppName("test_spark").setMaster("local")
# 创建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
# (T)->U
def func(x):
return x * x
rdd1 = rdd.map(lambda x: x * x)
print(rdd1.collect()) # [1, 4, 9, 16, 25]flatMap
功能:对rdd执行map操作,然后进行解除嵌套操作.
rdd =sc.parallelize(['hello itcast world', 'world itheima itheima', 'pyspark python spark'])
# 相当于js的flatMap 平铺
rdd1 = rdd.flatMap(lambda x: x.split(' '))
print(rdd1.collect())
# ['hello', 'itcast', 'world', 'world', 'itheima', 'itheima', 'pyspark', 'python', 'spark']readuceByKey
功能:
针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(valve)的聚合操作.
使用 flatMap 的时候,如果输入的是一个元素,应用函数之后的输出可能是零个、一个或多个元素。不同于 map 函数,flatMap 在应用函数后会“扁平化”结果,也就是说它会将所有输出元素合并到一个列表中,而不是映射到一个新的 RDD 中的元素。
rdd.reduceByKey(func)
# func:(V,V)->V
#接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致
rdd = sc.parallelize([('男',99),('男',88),('女',77),('女',66)])
rdd1 =rdd.reduceByKey(lambda a,b:a+b)
# [('男', 187), ('女', 143)]
rdd = sc.parallelize([1, 2, 3])
def f(x):
return (x, x * x)
rdd.flatMap(f).collect()
# 输出将是:
# [1, 1, 2, 4, 3, 9]
# 函数 f 对于每个元素返回一个元组(原始值和它的平方)。flatMap 将这些元组扁平化成单个列表。练习案例1
import os
# 构建执行环境入口对象
from pyspark import SparkConf, SparkContext
os.environ['PYSPARK_PYTHON'] = 'D:\python\python.exe'
# 创建SparkConf对象
conf = SparkConf().setAppName("test_spark").setMaster("local")
# 创建SparkContext对象
sc = SparkContext(conf=conf)
# 读取数据文件
rdd = sc.textFile('input.txt')
# 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 转化为(word,1)的元组形式
word_with_one_rdd = word_rdd.map(lambda x: (x, 1))
# 按照key进行分组,然后进行聚合操作
result_rdd = word_with_one_rdd.reduceByKey(lambda x, y: x + y)
# 输出结果
print(result_rdd.collect())filter
功能:对RDD进行过滤操作,返回满足条件的元素
rdd.filter(lambda x: x > 2)
# func:(T)->bool 接收一个参数,返回一个布尔值 为True则保留,为False则过滤
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd.filter(lambda x: x % 2 == 0)
print(rdd2.collect())
# [2, 4]dictinct
功能:对RDD进行去重操作,返回去重后的RDD
rdd.distinct()
# 去重操作,返回一个新的RDD
rdd = sc.parallelize([1, 2, 3, 2, 1, 4, 5, 4])
rdd2 = rdd.distinct()
print(rdd2.collect())
# [1, 2, 3, 4, 5]sortBy
功能:对RDD进行排序操作,返回排序后的RDD
rdd.sortBy(func,ascending=True,numPartitions=1)
# func:(T)->U 接收一个参数,返回一个值,用于排序
# ascending:bool 是否升序排列,默认True
# numPartitions:int 并行度,默认None,表示使用默认的并行度 用多少分区排序
rdd.sortBy(lambda x: x)
# 按照lambda表达式中的条件进行排序,返回一个新的RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 3), ('d', 2), ('e', 1)])
rdd1 = rdd.sortBy(lambda x: x[1])
print(rdd1.collect())
# [('a', 1), ('e', 1), ('b', 2), ('d', 2), ('c', 3)]
rdd2 = rdd.sortBy(lambda x: x, ascending=False, numPartitions=2)
print(rdd2.collect())
# [1, 2, 3, 4, 5]练习案例2
需求,复制以上内容到文件中,使用Spark读取文件进行计算:
- 各个城市销售额排名,从大到小
- 全部城市,有哪些商品类别在售卖
- 北京市有哪些商品类别在售卖
file_rdd = sc.textFile('orders.txt')
json_str_rdd = file_rdd.flatMap(lambda line: line.split('|'))
dict_rdd =json_str_rdd.map(lambda x: loads(x))
#(城市,销售额)
city_with_money_rdd = dict_rdd.map(lambda x: (x['areaName'],int(x['money'])))
city_result_rdd = city_with_money_rdd.reduceByKey(lambda c,m: c+m)
result1_rdd = city_result_rdd.sortBy(lambda x : x[1],False,1)
category_rdd = dict_rdd.map(lambda x: x['category']).distinct()
bj_data_rdd = dict_rdd.filter(lambda x: x['areaName'] == '北京')
result3_rdd = bj_data_rdd.map(lambda x: x['category']).distinct()数据输出
collect
功能:将RDD中的数据全部收集到Driver端,并返回一个
list列表
rdd.collect()
reduce
功能:对RDD中的数据进行聚合操作,返回一个值
rdd.reduce(func)
# func:(T,T)->T 接收2个参数,返回一个值,用于聚合
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd1 = rdd.reduce(lambda x, y: x + y)
print(rdd1)
# 15take
功能:从RDD中取出前n个元素,返回一个
list列表
rdd.take(n)
# n:int 取出前n个元素
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd1 = rdd.take(3)
print(rdd1)
# [1, 2, 3]count
功能:返回RDD中元素的数量
rdd.count()
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd1 = rdd.count()
print(rdd1)
# 5注意:
调用保存文件的算子,需要配置Hadoop依赖
- 下载Hadoop:安装包
- 解压到电脑任意位置
- 在Python代码中使用os模块配置:
os.environ['HADOOP_HOME']='HADOOP解压文件夹路径' - 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- 下载
hadoop.dlL,并放入:C:/Nindows/System32文件夹内
修改rdd分区为1个
- SparkConf对象设置属性全局并行度为1:
conf = SparkConf().setAppName("test_spark").setMaster("local").set("spark.default.parallelism", "1")- 创建RDD的时候设置(parallelize方法传入numSlices参数为1)
rdd = sc.parallelize([1, 2, 3, 4, 5], 1)
rdd = sc.parallelize([1, 2, 3, 4, 5], numSlices=1)saveAsTextFile
功能:将RDD中的数据保存到文件系统中,文件格式为文本格式, 有几个分区就输出多少个结果文件
rdd.saveAsTextFile(path)
# path:str 保存的文件路径
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.saveAsTextFile('output') # 如果报错需要安装hapoop依赖 输出到文件夹saveAsSequenceFile
功能:将RDD中的数据保存到文件系统中,文件格式为SequenceFile格式
rdd.saveAsSequenceFile(path)
# path:str 保存的文件路径
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 3), ('d', 2), ('e', 1)])
rdd.saveAsSequenceFile('output.seq')搜索引擎日志分析
需求
读取文件转换成RDD,并完成:
- 打印输出:热门搜索时间段(小时精度)Top3
- 打印输出:热门搜索词Top3
- 打印输出:统计黑马程序员关键字在哪个时段被搜索最多
- 将数据转换为JSON格式,写出为文件
rdd = sc.textFile('search_log.txt')
result1 = rdd.map(lambda x: x.split('\t')). \
map(lambda x: x[0][:2]). \
map(lambda x: (x, 1)). \
reduceByKey(lambda x, y: x + y). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(3)
result2 = rdd.map(lambda x: (x.split('\t')[2], 1)). \
reduceByKey(lambda x, y: x + y). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(3)
result3 = rdd.map(lambda x: x.split('\t')).filter(lambda x: x[2] == '黑马程序员'). \
map(lambda x: (x[0][:2], 1)). \
reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(1)
rdd.map(lambda x: x.split('\t')).map(lambda x: {'time':x[0],'user_id':x[1],'keyword':x[2],"rank1":x[3],"rank2":x[4],"url":x[5]}).saveAsTextFile('test_json')大数据分布式集群运行
未完待续..
python 高阶技巧
闭包
Python 中的闭包是一个相对高级的概念,它涉及到函数的嵌套及其作用域。闭包,简单来说,是一个函数,这个函数捕获并包含了它所在的作用域中的变量,即便这个作用域已经执行结束。
闭包的创建涉及到三个要素:
- 必须有一个嵌套函数(即内部函数)。
- 内部函数必须引用外部函数(包含内部函数的那个函数)中的变量。
- 外部函数的返回值必须是内部函数。
优点:
- 实现了数据隐藏,保护了函数内部变量不被外界修改
- 无需定义全局变量即可实现通过函数,持续的访问、修改某个值
缺点:
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存
nonlocal关键字:
- 用于在闭包中修改外部函数的变量
def outer():
x = 10
def inner():
nonlocal x #非局部 声明使用外部函数的变量
x += 1
print(x)
return inner
f = outer()
f() # 11
f() # 12
------
def make_multiplier(x):
# 这里定义了一个内部函数
def multiplier(n):
# 内部函数 multiplier 引用了外部函数 make_multiplier 的参数 x
return n * x
# make_multiplier 返回了内部函数 multiplier
return multiplier
# 使用闭包
times3 = make_multiplier(3)
times5 = make_multiplier(5)
print(times3(10)) # 输出: 30
print(times5(10)) # 输出: 50装饰器
装饰器(Decorator)是 Python 高阶函数的一种应用,它能在不改变函数源代码的前提下,动态地给函数增加功能。
def my_decorator(func):
def hello():
print("Hello, World!")
func()
return hello
def say_hello():
print("Hello, Python!")
say_hello = my_decorator(say_hello) # hell()
say_hello()
# Hello, World!
# Hello, Python!def my_decorator(func):
def wrapper(*args, **kwargs):
# 在被装饰的函数前可以执行一些代码
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
# 在被装饰的函数后可以执行一些代码
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.带参数的装饰器:
def my_decorator(num):
def wrapper(func):
def inner_wrapper(*args, **kwargs):
result = func(*args, **kwargs)
print(num)
return result
return inner_wrapper
return wrapper
@my_decorator(num=10) # my_decorator(10)(say_hello) = inner_wrapper
def say_hello(a, b, c):
print("Hello, World!")
return a+b+c
result = say_hello(1,3,4)
print(result)
# Hello, World!
# 10
# 8设计模式
设计模式(Design Pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。
单例模式
单例模式(Singleton Pattern)是一种常用的软件设计模式,它确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个实例可以全局访问。
单例模式就是对一个类,只获取其唯一的类实例对象,持续复用它。
- 节省内存
- 节省创建对象的开销
# 单例模式的实现
class Singleton(object):
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kwargs)
return cls._instance
# 单例模式的使用
s1 = Singleton()
s2 = Singleton()
print(id(s1), id(s2))
# 打印输出:
# 140411222224256 140411222224256class StrTools:
pass
str_tool = StrTools()from str_tools import str_tool
str1 = str_tool()
str2 = str_tool()
print(id(str1), id(str2))
# 打印输出:
# 140411222224256, 140411222224256工厂模式
工厂模式(Factory Pattern)是一种创建型设计模式,它提供了一种创建对象的最佳方式。
- 大批量创建对象的时候有统一的入口,易于代码维护
- 当发生修改,仅修改工厂类的创建方法即可
- 符合现实世界的模式,即由工厂来制作产品(对象)
# 工厂模式的实现
class Shape(object):
def draw(self):
pass
class Circle(Shape):
def draw(self):
print('Drawing Circle')
class Rectangle(Shape):
def draw(self):
print('Drawing Rectangle')
class ShapeFactory(object):
@staticmethod
def get_shape(shape_type):
if shape_type == 'circle':
return Circle()
elif shape_type =='rectangle':
return Rectangle()
else:
return None
# 工厂模式的使用
shape1 = ShapeFactory.get_shape('circle')
shape2 = ShapeFactory.get_shape('rectangle')
shape3 = ShapeFactory.get_shape('triangle')
if shape1:
shape1.draw()
if shape2:
shape2.draw()
if shape3:
shape3.draw()
# 输出:
# Drawing Circle
# Drawing Rectangle
# None多线程
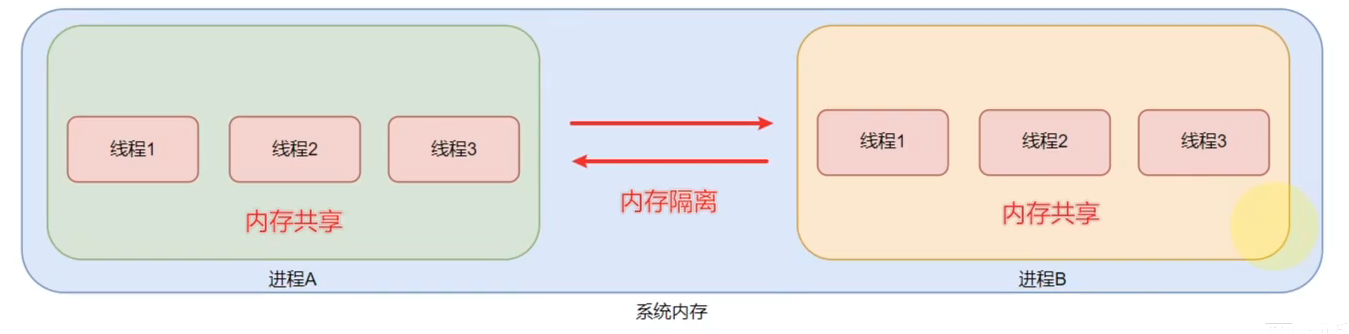
进程和线程
进程(process):就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程D方便系统管理。
线程(thread):线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
进程就好比一家公司,是操作系统对程序进行运行管理的单位
线程就好比公司的员工,进程可以有多个线程(员工),
进程实际的工作者操作系统中可以运待多个进程,即多任务运行 一个进程内可以运行多个线程,即多线程运行
注意:
进程之间是内存隔离的,即不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所。
线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的。这就好比,公司员工之间是共享公司的办公场所。
并行执行
INFO
- 多个进程同时在运行,即不同的程序同时运行,称之为:
多任务并行执行 - 一个进程内的多个线程同时在运行,称之为:
多线程并行执行
并行(parallel):指两个或多个事件在同一时刻发生。
并发(concurrency):指两个或多个事件在同一时间间隔发生。
并行是指两个或多个事件在同一时刻发生,并发是指两个或多个事件在同一时间间隔发生。
也就是比如一个Python程序其实是完全可以做到:
- 一个线程在输出你好
- 一个线程在输出Hello
像这样一个程序在同一时间做两件乃至多件不同的事情,我们就称之为:多线程并行执行
多线程编程
Python的多线程可以通过threading模块来实现。
import threading
import time
def task():
print("Task started")
time.sleep(3)
print("Task finished")
thread1 = threading.Thread(target=task)
thread1.start()
thread2 = threading.Thread(target=task)
thread2.start()
thread1.join()
thread2.join()Socket
网络编程中,Socket(套接字)是通信的基石,是支持TCP/IP协议的
网络通信的基本操作单元。
Socket:负责进程之间的网络数据传输,好比数据的搬运工。
- 服务器Socket:由操作系统内核创建,应用程序可以调用
bind()和listen()方法来设置服务器的IP地址和端口号,等待客户端的连接请求。
服务器端
- 创建套接字
import socket
# 创建TCP/IP套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定IP地址和端口号
server_address = ('127.0.0.1', 6789)
server_socket.bind(server_address)
# 监听连接
server_socket.listen(1)- 接收客户端连接请求
# 等待客户端连接
client_socket, client_address = server_socket.accept()- 接收客户端数据
# 接收客户端数据
data = client_socket.recv(1024)- 发送数据给客户端
# 发送数据给客户端
client_socket.sendall(b'Hello, world')- 关闭套接字
# 关闭套接字
client_socket.close()
server_socket.close()客户端
- 创建套接字
import socket
# 创建TCP/IP套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)- 连接服务器
# 连接服务器
server_address = ('127.0.0.1', 6789)
client_socket.connect(server_address)- 发送数据给服务器
# 发送数据给服务器
client_socket.sendall(b'Hello, world')- 接收服务器数据
# 接收服务器数据
data = client_socket.recv(1024)- 关闭套接字
# 关闭套接字
client_socket.close()import socket
socket_client = socket.socket()
socket_client.connect(('127.0.0.1',8888))
while True:
message = input("Enter message: ")
socket_client.send(message.encode())
if message == 'exit':
break
response = socket_client.recv(1024).decode()
print(response)
socket_client.close()正则表达式
基础匹配
正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。
re模块:Python的标准库,用于处理正则表达式。match():从字符串的起始位置匹配正则表达式,返回一个匹配对象。search():扫描整个字符串并返回第一个成功的匹配。findall():找到字符串中所有匹配正则表达式的子串,并返回一个列表。sub():替换字符串中匹配正则表达式的子串。
import re
s = "1python itheima python"
str = re.match(r"itheima",s) # ,前缀 r 表示原始字符串(raw string)。使用原始字符串时,反斜杠 \ 不会被当做转义字符处理,它只是表示一个普通字符
# print(str.group())
reg = re.compile(r"python")
print(reg.findall(s))
# ['python', 'python']元字符匹配
| 字符 | 功能 |
|---|---|
. | 匹配任意字符,除了换行符 |
[] | 匹配括号内的任意字符 |
\d | 匹配任意数字,等价于[0-9] |
\D | 匹配任意非数字,等价于[^0-9] |
\s | 匹配任意空白字符,等价于[\t\n\r\f\v] |
\S | 匹配任意非空白字符 |
\w | 匹配任意字母、数字、下划线 |
\W | 匹配任意非字母、数字、下划线 |
\b | 匹配单词边界 |
\B | 匹配非单词边界 |
\n | 匹配换行符 |
\t | 匹配制表符 |
\r | 匹配回车符 |
\f | 匹配换页符 |
\v | 匹配垂直制表符 |
import re
s = "1python itheima python"
# 匹配任意数字
print(re.findall(r"\d",s)) # 字符串的标记,表示当前字符串是原始字符串,即内部的转义字符无效而是普通字符
# ['1']数量匹配:
| 字符 | 功能 |
|---|---|
* | 匹配前面的字符0次或无限次 |
+ | 匹配前面的字符1次或无限次 |
? | 匹配前面的字符0次或1次 |
{n} | 匹配前面的字符n次 |
{n,} | 匹配前面的字符n次或更多次 |
{n,m} | 匹配前面的字符n到m次 |
边界匹配:
| 字符 | 功能 |
|---|---|
^ | 匹配字符串的开始位置 |
$ | 匹配字符串的结束位置 |
\b | 匹配一个单词的边界 |
\B | 匹配非单词边界 |
\A | 匹配字符串的开始位置 |
\Z | 匹配字符串的结束位置,如果是存在换行,只匹配到换行前的位置 |
分组匹配:
| 字符 | 功能 |
|---|---|
( ) | 匹配括号内的表达式,并记住匹配的文本,可以用于替换 |
| | 匹配左右两个表达式中的任何一个 |
字符集
| 字符 | 功能 |
|---|---|
[abc] | 匹配a、b、c中的任意一个字符 |
[^abc] | 匹配除了a、b、c之外的任意字符 |
[a-z] | 匹配a到z的任意一个字符 |
[^a-z] | 匹配除了a到z之外的任意字符 |
[a-zA-Z] | 匹配任意一个字母 |
[^a-zA-Z] | 匹配任意一个非字母 |
[0-9a-zA-Z] | 匹配任意一个数字或字母 |
[^0-9a-zA-Z] | 匹配任意一个非数字或字母 |
[\d|\W] | 匹配任意一个数字或非数字字符 |
[^\d|\W] | 匹配任意一个非数字或非非数字字符 |
[\s|\S] | 匹配任意一个空白字符或非空白字符 |
[^\s|\S] | 匹配任意一个非空白字符或非非空白字符 |
[\w|\W] | 匹配任意一个字母、数字或下划线 |
递归
递归(Recursion)是一种编程技术,是指在函数的定义中使用函数自身调用自身的一种编程技巧。
递归函数有两个非常重要的部分,基本情况和递归情况:
- 基本情况(
Base Case): 这是递归结束的条件,没有它,递归将无限进行。基本情况用来处理最简单的情况,它不需要递归就能解决。 - 递归情况(
Recursive Case): 这是递归的核心,它是函数的功能。递归情况是指函数调用自身,并且在每次调用时,都要做一些处理。
def factorial(n):
# 基本情况
if n == 0:
return 1
# 递归情况
else:
return n * factorial(n-1)
print(factorial(5)) # 输出: 120