Python
字面量
注释
- 单行注释:
# - 多行注释:
'''或"""
变量
在程序运行时,能储存计算结果或能表示值的抽象概念。简单的说,变量就是在程序运行时,记录数据用的
变量名 = 值
- 变量名:只能包含字母、数字和下划线,且不能以数字开头
- 变量类型:动态语言,变量类型不固定,可以随时改变
- 变量作用域:局部变量、全局变量、内置变量
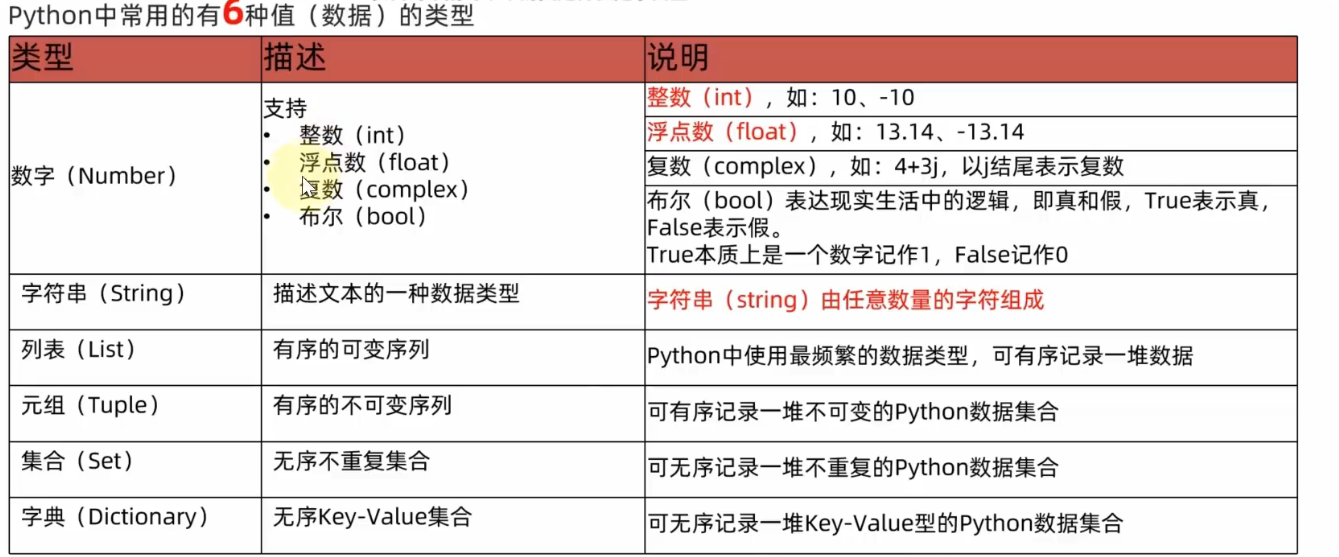
数据类型
TIP
string(字符串)、integer(整数)、float(浮点数)、boolean(布尔值)、list(列表)、tuple(元组)、set(集合)、dict(字典)
我们通过type(变量)可以输出类型,这是查看变量的类型还是数据的类型?
查看的是:变量存储的数据的类型。因为,变量无类型,但是它存储的数据有。
type() 函数可以用来获取变量的类型。
type(123) # <class 'int'>
type('hello') # <class'str'>
type(3.14) # <class 'float'>
type(True) # <class 'bool'>
type([1, 2, 3]) # <class 'list'>
type((1, 2, 3)) # <class 'tuple'>
type({1, 2, 3}) # <class'set'>
type({'name': 'Alice', 'age': 20}) # <class 'dict'>数据类型转换
int('123') # 123
str(123) # '123'
float(123) # 123.0
bool(1) # True
bool(0) # False
list('hello') # ['h', 'e', 'l', 'l', 'o']
tuple('hello') # ('h', 'e', 'l', 'l', 'o')
set('hello') # {'l', 'o', 'h', 'e'}
dict([('name', 'Alice'), ('age', 20)]) # {'name': 'Alice', 'age': 20}标识符
- 大小写敏感
- 不能以数字开头
- 不能使用关键字
- 不能使用特殊字符
标识符命名中,只允许出现:
- 英文
- 中文
- 数字
- 下划线
_
运算符
- 算术运算符:
+、-、*、/、//(取整)、%(取余)、** - 赋值运算符:
=、+=、-=、*=、/=、//=、%=、**= - 位移运算符:
<<、>> - 增量赋值运算符:
++、-- - 关系运算符:
==、!=、>、>=、<= - 逻辑运算符:
and、or、not - 位运算符:
&、|、^、~、<<、>> - 成员运算符:
in、not in - 身份运算符:
is、is not - 海象运算符:
:=允许在表达式中进行赋值操作- python
# 传统的写法需要两行 nums = [1, 2, 3, 4, 5] n = len(nums) #下面海象相当于把这里冗余的赋值语句省略掉了 if n > 3: # 这里也冗余了赋值语句 n := len(nums) print(f"列表的长度是{n},长度大于3。") # 使用海象运算符,可以在一行内完成 if (n := len(nums)) > 3: print(f"列表的长度是{n},长度大于3。")
字符串扩展
- 字符串连接:
+ - 字符串重复:
* - 字符串切片:
[start:end:step] - 字符串格式化:
%(占位符)"你好:%s" % ('小明')%s字符串%d整数%f浮点数%x十六进制整数%o八进制整数%e科学计数法
- 快速字符串:
f"内容{变量}"(不需要精度控制)
数字精度控制
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
- m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
- .n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例:
%5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。%5.2f:表示将浮点数的宽度控制在5位,小数点后精度控制在2位,如数字3.1415926,被设置为5.2f,就会变成:[空格]3.14。%.2f:表示将浮点数的精度控制在2位,如数字3.1415926,被设置为.2f,就会变成:3.14。
# 保留两位小数
print('{:.2f}'.format(3.1415926)) # 3.14
"""
{:.2f}'.format(3.141592653589793)是Python中字符串格式化的语法。在这个语法中:
· {}表示一个占位符,它将由format方法中的相应参数替换。
· :在占位符中引导后续的格式化选项。
· .2f表示格式化为浮点数,保留两位小数。
简单来说,这个表达式将数字3.141592653589793格式化为字符串,并保留两位小数,输出结果为'3.14'。
"""表达式的格式化
str.format()方法:"{0} {1}".format("hello", "world")字符串模板:
f"hello {len(name)}"("1 * 1 的结果是: %d" % (1 * 1))
数据输入
- 标准输入:
input()
使用input()语句可以从键盘获取输入使用一个变量接收(存储)iput语句获取的键盘输入数据即可
- 文件输入:
open()
布尔类型和比较运算符
布尔类型只有两个值:True和False,可以进行逻辑运算,比较运算符可以进行数值比较。
- 比较运算符:
==、!=、>、<、>=、<=
if语句的基本格式
如果条件成立,则执行if语句块中的代码;否则,执行else语句块中的代码。
if 条件表达式:
语句块1
elif 条件表达式:
语句块2
else:
语句块3判断语句的嵌套
if 条件表达式1:
语句块1
if 条件表达式2:
语句块2
else:
语句块3
else:
语句块4示例:
print('欢迎ikun网咖!')
if int(input("请输入你的年龄:")) >= 18:
print("你已经成年,如果身高符合要求,你才可以正常上网!")
if int(input("请输入你的身高(厘米):")) >= 170:
print("你已经达到了身高标准,可以正常上网了!")
else:
print("你还未达到身高标准,请回吧!")
else:
print("你还未成年,请在成年后再来!")match语句
类似switch语句,可以根据条件表达式的值,执行对应的代码块。
match语句是在 Python 3.10 版本中新引入的结构称为“模式匹配”,这是一个被用作语言结构的新式 switch 语句。
match 变量:
case 值1:
语句块1
case 值2:
语句块2
case 值3:
语句块3
case _:
语句块4
def http_status(status):
match status:
case 200:
return "OK"
case 404:
return "Not Found"
case 418:
return "I'm a teapot"
case _: # 默认情况 _
return "Something's wrong with the internet"
print(http_status(200)) # 输出 'OK'在以上代码中,match 将 status 变量与每个 case 中的值进行比较,如果存在匹配则执行对应的块。最后的 case _ 是一个默认情况,如果之前的值都不符合,则会执行它。
while循环的基础应用
重复执行语句块,直到条件表达式为False。
while 条件表达式:
语句块
while 条件表达式:
语句块
break # 跳出当前循环
if 条件bool表达式:
continue # 跳过当前循环,继续下一次循环知识补充:
print输出不换行
在print()函数中,如果要输出多个值,中间用逗号隔开,默认会自动加上空格,如果要输出不换行,可以用end=''参数。
print('hello', end='')
print('world')输出结果:
helloworld九九乘法表
i = 1 #层数
while i <= 9:
j = 1
while j <= i:
print(f"{j}*{i}={i * j}\t", end="")
j += 1
print('\n')
i += 1for i in range(1, 10):
for j in range(1, i+1):
print('{0}x{1}={2}\t'.format(j, i, i*j), end='')
print()for循环的基础语法
除了while循环语句外,Python同样提供了for循环语句。
两者能完成的功能基本差不多,但仍有一些区别:
- while循环的循环条件是自定义的,自行控制循环条件
- for循环是一种”轮询”机制,是对一批内容进行 逐一处理
TIP
同while循环不同,for循环是无法定义循环条件的。只能从被处理的数据集中,依次取出内容进行处理。所以,理论上讲,Python的for循环无法构建无限循环(被处理的数据集不可能无限大)
for 临时变量 in 可迭代对象:
语句块
for 变量 in 可迭代对象:
语句块
break # 跳出当前循环
if 条件bool表达式:
continue # 跳过当前循环,继续下一次循环
name = 'John'
for i in name:
print(i)
输出结果:
J
o
h
nname = 'itheima is a brand of itcast'
total = 0
# 1. 统计字符串中字母的个数
for i in name:
if i == 'a':
total += 1
print(f"字母 'a' 出现了 {total}")range()函数
for循环语句,本质上是遍历:序列类型
尽管除字符串外,其它的序列类型目前没学习到,但是不妨碍我们通过 学习range语句,获得一个简单的数字序列。
range()函数可以生成一个整数序列,可以用于for循环的循环条件。
语法:range(start, stop, [,step])
start:起始值,默认为0, 可以省略stop:终止值,不包含在序列中step:步长,默认为1
for i in range(1, 10):
print(i)变量作用域
- 局部变量:在函数内部定义的变量,只能在函数内部访问,函数执行完毕,变量就消失了。
- 全局变量:在函数外部定义的变量,可以在整个程序范围内访问。
- 内置变量:Python预定义的变量,比如
__name__、__doc__等。
for i in range(1, 10):
print(i)
print(i)
回看for循环的语法,我们会发现,将从数据集 (序列)中取出的数据赋值给:临时变量为什么是临时的呢?
i应该只在for循环内部使用,而不能在外部使用,所以,i是临时的。
如果我们想在外部使用i,那我们就需要将i定义为全局变量。
但是实际上却是能访问到的。这是不允许的,属于是变量提升了。continue和break语句
DANGER
continue和break语句只能在循环体中使用,不能在函数体中使用。
在嵌套循环中,只能作用在所在的循环上,无法对上层循环起作用。
continue:跳过当前循环,继续下一次循环。break:跳出当前循环。
for i in range(1, 10):
if i == 5:
continue #当i等于5时,跳过当前循环,继续下一次循环
print(i)
if i == 8:
break #当i等于8时,跳出当前循环import random
total_money = 10000
for employee in range(1, 21):
if total_money <= 0:
print("工资发完了,下个月领取吧")
break
effected = random.randint(1, 10)
if effected < 5:
print(f"员工{employee},绩效分{effected},低于5,不发工资,下一位")
continue
total_money -= 1000
print(f"向员工{employee}发放1000元工资,剩余{total_money}元")函数
解决代码冗余,提高代码可读性,提高代码复用性。
函数是一段代码,可以重复使用,可以传递参数,可以返回值。
- 定义函数:
def 函数名(参数列表):- python
def 函数名(参数): print(f"Hello, {name}!") return 返回值
- 调用函数:
函数名(参数) - 文档字符串:
函数名.__doc__
def say_hello(name): # 函数name为形参,形式上的。
"""
打印问候语
"""
print(f"Hello, {name}!")
#return None # 类似函数没有返回值,返回值为None。
# say_hello 默认返回值为None
say_hello("Alice") # "Alice" 为实参,实际上的。
say_hello.__doc__ # 打印函数的文档字符串函数的说明文档
def func(x:int,y:int):
"""
This is a function to add two numbers.
:param x:形参x的类型为int
:param y:形参y的类型为int
:return: 返回值类型为int
"""
func()函数变量作用域
- 局部变量:在函数内部定义的变量,只能在函数内部访问,函数执行完毕,变量就消失了。
- 全局变量:在函数外部定义的变量,可以在整个程序范围内访问。
- 内置变量:Python预定义的变量,比如
__name__、__doc__等。
def inner_func():
y = 20 # 局部变量
print(y) # 20
inner_func()
print(y) # ❌ y is not defined函数内部使用全局变量,需要使用global关键字声明。 否则函数内部声明的变量,只在函数内部有效。(相当于重新声明了一个名字重复的变量)
x = 10 # 全局变量
def outer_func():
global x # ✅!!!声明全局变量
x = 20 # 修改全局变量
print(x) # 20
outer_func()
print(x) # 20x = 10 # 全局变量
def outer_func():
x = 20 # 试图修改全局变量 声明了一个函数局部名字重复的变量
print(x) # 20
outer_func()
print(x) # 10 全局变量并未修改成功银行存款、取款、查询余额的案例:
money = 5000000
name = input("Enter your name: ")
def query(show_header):
if show_header:
print("-----------------查询余额-----------------")
print(f"{name}您的账户余额为:{money}")
def saving(num):
global money
money += num
print('-----------------存款-----------------')
query(False)
def get_money(num):
global money
if money >= num:
money -= num
print('-----------------取款成功-')
query(False)
else:
print('-----------------取款失败-')
query(False)
def main():
print("-------------主菜单-----------")
print("1.查询余额")
print("2.存款")
print("3.取款")
print("4.退出")
while True:
main()
choice = input("请输入您的选择:")
if choice == '1':
query(True)
elif choice == '2':
num = int(input("请输入存款金额:"))
saving(num)
elif choice == '3':
num = int(input("请输入取款金额:"))
get_money(num)
elif choice == '4':
print("欢迎下次光临!")
break函数的进阶
多返回值
函数可以返回多个值,返回值可以是任意类型。
可以用到解构赋值 x,y = 1,2,3
def return_num():
return 1
return 2
print(return_num()) # 1 第一个return执行后就终止了
def test_return():
return 1,2
x,y = test_return() # 元组的解构赋值
print(x) # 1
print(test_return()) # (1, 2) 多个返回值,返回一个元组多种参数使用形式 ‼️
位置参数
位置参数是指函数调用时,按照函数定义时的顺序,依次传入参数。一一对应的关系
def add(x, y):
return x + y
print(add(1, 2)) # 3 1对应x,2对应y关键字参数
关键字参数是指函数调用时,按照函数定义时指定的参数名,传入参数。"key=value"的形式。
注意:
函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面(很关键❤️),但关键字参数之间不存在先后顺序
def add(x, y):
return x + y
print(add(y=2, x=1)) # 3 形参名对应实参名,不用考虑顺序
print(add(1, y=2)) # 3 可以和位置参数混用 位置参数在前,关键字参数在后默认参数
默认参数是指函数定义时,给参数指定默认值,当函数调用时,如果没有传入参数,则使用默认值。
def add(x, y=1):
return x + y
print(add(1)) # 2
print(add(1, 2)) # 3变量参数(不定长参数)
变量参数是指函数定义时,最后一个参数为可变参数,可以传入任意数量的参数。
注意:
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
类似于js里面的arguments或者剩余参数
位置传递
pythondef info(*args): #args是元组类型 print(args) info("hello","world") # ('hello', 'world')关键字传递
pythondef info(**kwargs): #kwargs是字典类型 print(kwargs) info(name="Alice", age=20) # {'name': 'Alice', 'age': 20}位置和关键字混合传递
pythondef info(name, *args, **kwargs): #依然遵循位置参数在前,关键字参数在后 print(name) print(args) print(kwargs) info("Alice", "hello", "world", age=20) # Alice # ('hello', 'world') # {'age': 20}函数作为参数传递
pythondef test_func(compute): result = compute(10, 20) # 调用函数 计算逻辑是在compute函数中 print(result) def compute(x, y): return x + y test_func(compute) # 30
递归函数
递归函数是指函数自己调用自己。
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n-1)
print(factorial(5)) # 120匿名函数(lambda)
匿名函数是指没有函数名的函数。
注意:
匿名函数只能有一个表达式,不能有return语句,只能有一行代码。
语法:lambda 参数列表:表达式 这里的表达式的结果就是这个lambda函数的返回值,自带隐形的return语句。
lambda 函数本身是可以重复使用的,如果你将它赋值给一个变量。在 Python 中,lambda 函数和使用 def 关键字创建的函数一样,都是对象,可以被赋值给变量,加以存储和重复使用。
但通常,lambda 函数被用作匿名函数,常常在需要一个函数作为参数的地方临时创建。由于它们通常很简短,所以不一定非要赋给一个变量;你可以直接将它们作为参数传递给其他函数。
# 将 lambda 函数赋值给一个变量
add_ten = lambda x: x + 10 #赋予变量,可以多次使用
#类似于
def xx(x):
return x + 10
# 多次使用这个函数
print(add_ten(5)) # 输出: 15
print(add_ten(20)) # 输出: 30
# 在一个高阶函数调用中直接使用 lambda 函数
# 对列表中的每一个元素进行平方处理
squared = map(lambda x: x ** 2, [1, 2, 3, 4, 5])
#这里的 lambda 函数用于 map 函数调用中,用以应用到列表中的每个元素。没有必要赋值给一个变量,因为它在这里只使用了一次,其目的是为了写出更简洁的代码。
#因此,lambda 函数不仅可以重复使用,而且可以用作临时的匿名函数。它的使用方式取决于具体场景的需求。
print(list(squared)) # 输出: [1, 4, 9, 16, 25]装饰器
装饰器是一种函数,它可以修改另一个函数的行为。
def my_decorator(func):
def wrapper(*args, **kwargs):
print("before function")
result = func(*args, **kwargs)
print("after function")
return result
return wrapper
@my_decorator
def my_func(x, y):
return x + y
print(my_func(1, 2)) # 3偏函数
偏函数是指将一个函数的某些参数固定住,返回一个新的函数。
from functools import partial
def add(x, y):
return x + y
add_10 = partial(add, 10)
print(add_10(5)) # 15数据容器
容器是一种数据结构,用于存储、组织和管理数据。
Python中有5种基本的数据容器:
- 列表:
list[value,value] - 元组:
tuple(value,value) - 集合:
set{value,value} - 字典:
dict{key:value} - 字符串:
str''
列表
列表是一种有序的集合,可以存储任意类型的数据。每个数据称为元素,元素可以是任意类型。
- 通过索引访问列表元素,索引从
0开始。(-1表示最后一个元素依此类推)
- 创建列表:
list_name = [value1, value2, value3] - 访问列表元素:
list_name[index] - 修改列表元素:
list_name[index] = new_value - 追加元素:
list_name.append(value) - 插入元素:
list_name.insert(index, value) - 删除元素:
list_name.remove(value)或del list_name[index]或list_name.pop([,index]) - 列表长度:
len(list_name) - 列表切片:
list_name[start:end:step] - 列表分类:
list_name.sort(key,reverse)或list_name.reverse()
# 创建列表
my_list = [1, 2, 3, 4, 5]
# 访问列表元素
print(my_list[0]) # 1
# 修改列表元素
my_list[0] = 10
print(my_list[0]) # 10
# 追加元素
my_list.append(6)
print(my_list) # [10, 2, 3, 4, 5, 6]
# 插入元素
my_list.insert(1, 100)
print(my_list) # [10, 100, 2, 3, 4, 5, 6]
# 删除元素
my_list.remove(100)
print(my_list) # [10, 2, 3, 4, 5, 6]
# 列表长度
print(len(my_list)) # 6
# 列表切片
print(my_list[1:4]) # [2, 3, 4]
print(my_list[::2]) # [10, 3, 5]
# 列表分类
my_list = [["a",33],["b",65],["c",11]]
def sort_by_key(item):
return item[1]
my_list.sort(key=sort_by_key, reverse=True)
# 也可以用lambda函数 参数为my_list中的元素
my_list.sort(key=lambda x:x[1], reverse=True)
print(my_list) # [['b', 65], ['a', 33], ['c', 11]]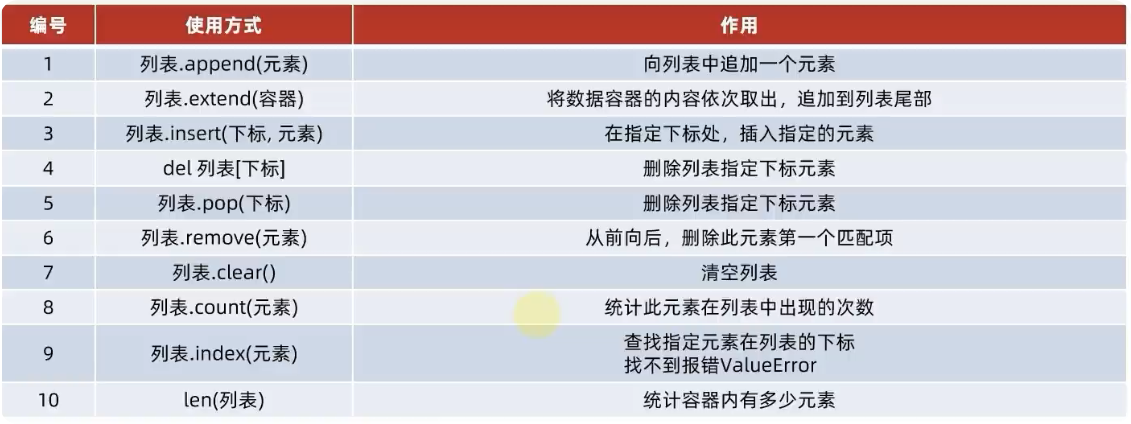
列表遍历
遍历列表元素,可以用
for循环或while循环。 遍历,迭代。
my_list = [1, 2, 3, 4, 5]
#while循环
index = 0
while index < len(my_list):
print(my_list[index])
index += 1
#for循环
for item in my_list:
print(item)小案例:
new_list = []
for item in list(range(1, 11)):
if item % 2 == 0:
new_list.append(item)
--------------
new_list = []
old_list = list(range(1, 11))
while len(old_list):
result = old_list.pop()
if result % 2 == 0:
new_list.append(result)元组
元组是不可变的列表,一旦创建,元素不能修改,可以多个数据,可重复,可嵌套,可循环。
- 通过索引访问元组元素,索引从
0开始。(-1表示最后一个元素依此类推) - 元组的元素类型可以不同,可以包含不同的数据类型。
- 元组的创建语法:
tuple_name = (value1, value2, value3) - 方法:
count()、index()、len(tuple_name)
# 创建元组
my_tuple = (1, 2, 3, 4, 5)
my_tuple = 1, 2, 3 # 元组的创建语法
my_tuple = ([1, 2, 3]) #是迭代就行
my_tuple = (1, 2, 3), (4, 5, 6) # 元组的嵌套
my_tuple = ((1, 2, 3), (4, 5, 6)) # 元组的嵌套
my_tuple = (1) ❌ <class 'int'> 整数类型而非元组类型
my_tuple = (1,) ✅ 单个元素的元组,需要加上逗号
# 访问元组元素
print(my_tuple[0]) # 1
# 元组的元素类型可以不同
my_tuple = (1, 'hello', True)
print(my_tuple[1]) # hello
# 元组的创建语法
my_tuple = 1, 2, 3
print(my_tuple) # (1, 2, 3)小案例:
studentInfo = '周杰伦', 11, ['football', 'music']
print(studentInfo.index(11)) # 1
print(studentInfo[0]) # 周杰伦
del studentInfo[-1][0] # 删除列表中的元素
# studentInfo[-1].remove('football')
# studentInfo[-1].pop(0)
studentInfo[-1].append('coding') # 追加元素
print(studentInfo) # ('周杰伦', 11, ['music', 'coding'])TIP
如果你需要删除指定位置的元素并可能使用该元素,用
pop()(需要返回值的话)。如果你想要删除一个特定值的元素(且只删除第一个找到的),用
remove()。如果你需要基于索引删除一个或多个元素,并且不需要返回值,用
del studentInfo[start:end:step]可以用切片来删除元素。
字符串
尽管字符串看起来并不像:列表、元组那样,一看就是存放了许多数据的容器。但不可否认的是,字符串同样也是数据容器的一员。
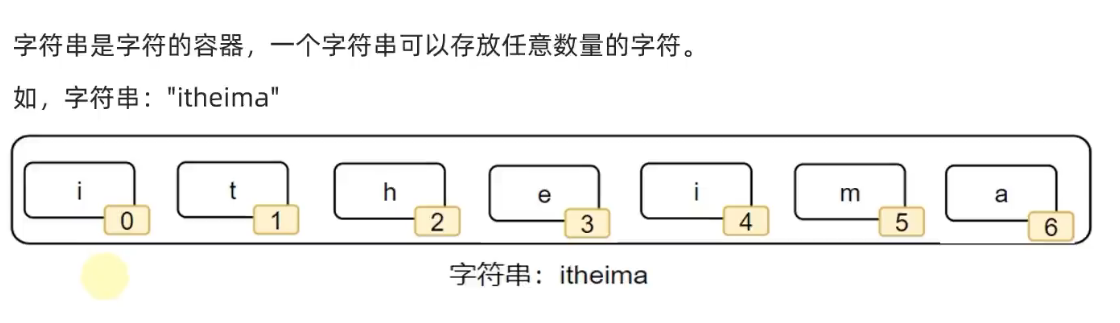
跟列表、元组一样,字符串也有索引、切片、拼接、格式化等操作。(字符串不可变,不能修改元素,不能删除特定下标的元素,不能插入元素)
# 创建字符串
my_string = "hello world"
# 访问字符串元素
print(my_string[0]) # h
# 修改字符串元素
my_string[0] = 'X'
print(my_string) ❌ 字符串是不可变的,不能修改元素
my_string.remove('l')
print(my_string) ❌ 字符串是不可变的,不能删除特定下标的元素 (remove,pop,del)
my_string.insert(1, 'l')
print(my_string) ❌ 字符串是不可变的,不能插入元素 (insert append)
1. 字符串的替换:`replace(old_str, new_str)`
- 相当于拷贝了一份原字符串,然后用新字符串替换掉原字符串中的指定内容。返回一个新的字符串。
2. 字符串的分割:`split(sep)`
- 按照指定分隔符分割字符串,返回一个列表。
3. 字符串的去除空白:`strip([chars])` 默认去除空白符。实际上 chars 参数并非指定单个前缀或后缀;而是会移除参数值的所有组合
- print('www.example.com'.strip('w.com')) # example 里面的组合
3. 字符串的连接:`join(list)`
- 按照指定列表中的元素,连接成一个字符串。
4. 字符串的格式化:`format()`
- 格式化字符串,用`{}`占位符来替换。
5. 字符串的大小写转换:`lower()`、`upper()`
6. 字符串的长度:`len(string)`
7. 字符串的切片:`string[start:end:step]`切片
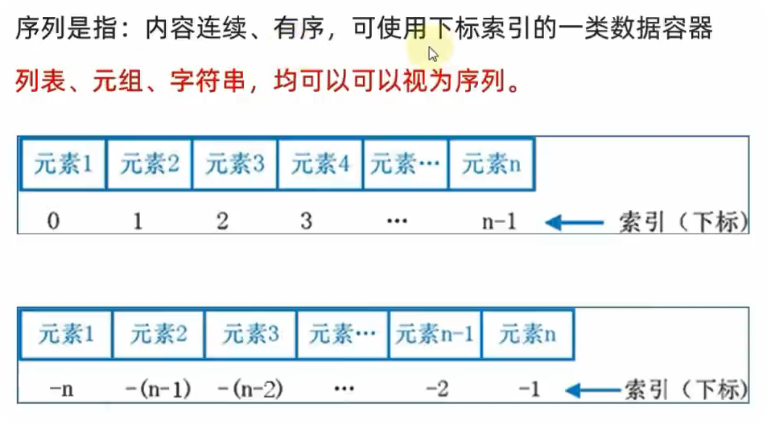
切片是指从序列(list、tuple、str)中取出一部分元素,并生成一个新的序列。
语法:序列[开始索引:结束索引:步长]
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔步
- 步长1表示,一个个取元素
- 步长2表示,每次跳过1个元素取
- 步长N表示,每次跳过N-1个元素取
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
my_list = list(range(0,7))
# 切片
print(my_list[1:4]) # [2, 3, 4] 不写step默认为1
print(my_list[::2]) # [1, 3, 5] 起始下标和结束下标都不写从头到尾,步长为2
print(my_list[::-1]) # [6, 5, 4, 3, 2, 1] 步长为负数,反向取
print(my_list[3:1:-1]) # [3, 2] 步长为-1,反向取
print(my_list[::-2]) # [6,4,2,0] 步长为-2,跳过2个元素取小案例:
my_str = "万过薪月,员序程马黑来,nohtyP学"
str_list = my_str.split(',')
str_list[1].replace('来', '')[::-1] #黑马程序员
str_list[1][-2::-1] #黑马程序员
my_str[9:4:-1] #黑马程序员集合
集合是一种无序的集合,集合中的元素不能重复。
IMPORTANT
因为集合是无序的,所以不能通过索引访问元素,只能通过元素本身来访问。
集合和列表一样,是允许修改的。
基本语法:
- 创建集合:
set_name = {value1, value2, value3} - 访问集合元素:
set_name[index] - 修改集合元素:
set_name[index] = new_value - 追加元素:
set_name.add(value) - 删除元素:
set_name.remove(value)或del set_name[index] - 集合长度:
len(set_name) - 集合运算:
union() 并集、intersection() 交集、difference() 差集、symmetric_difference() 对称差
# 创建集合
my_set = {1, 2, 3, 4, 5}
# 修改集合元素
my_set[0] = 10不能修改元素
# 追加元素
my_set.add(6)
print(my_set) # {1, 2, 3, 4, 5, 6}
A = {1, 2, 3, 4, 5}
B = {4, 5, 6, 7, 8}
print(A ^ B)
# {1, 2, 3, 6, 7, 8}
print(A.symmetric_difference(B))
# {1, 2, 3, 6, 7, 8}
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}
# A 和 B 的差集,即A中有而B中没有的元素 求同存异 以A为基准
C = A.difference(B)
print(C) # 结果将是 {1, 2}
C = A - B
print(C) # 结果同样是 {1, 2}
# A 和 B 的消除交集
C = A.difference_update(B)
print(C) # 结果将是 {1, 2}
C = A -= B
print(C) # 结果同样是 {1, 2}
# A 和 B 的并集,即A中有或B中有的所有元素
C = A.union(B)
print(C) # 结果将是 {1, 2, 3, 4, 5, 6}
C = A | B
print(C) # 结果同样是 {1, 2, 3, 4, 5, 6}
# A 和 B 的交集,即A中有且B中也有的所有元素
C = A.intersection(B)
print(C) # 结果将是 {3, 4}
C = A & B
print(C) # 结果同样是 {3, 4}字典
字典是一种无序的键值对集合,字典中的键必须是唯一的,值可以重复。 key-value pairs
基本语法:
- 创建字典:
dict_name = {key1:value1, key2:value2, key3:value3} - 访问字典元素:
dict_name[key] - 修改字典元素:
dict_name[key] = new_value - 追加元素:
dict_name[new_key] = new_value - 删除元素:
del dict_name[key] dict_name.pop(key) dict_name.popitem() - 字典长度:
len(dict_name) - 字典键值对:
dict_name.items() - 字典键:
dict_name.keys() - 字典值:
dict_name.values()
# 创建字典
my_dict = {'name': '张三', 'age': 20, 'gender': '男'}
# 访问字典元素
print(my_dict['name']) # 张三
# 修改字典元素
my_dict['age'] = 25 # 直接修改值
print(my_dict) # {'name': '张三', 'age': 25, 'gender': '男'}
my_dict['age'] = 20 # 再次修改值
print(my_dict) # {'name': '张三', 'age': 20, 'gender': '男'}
# 追加元素
my_dict['city'] = '北京'
print(my_dict) # {'name': '张三', 'age': 20, 'gender': '男', 'city': '北京'}
# 删除元素
del my_dict['age']
print(my_dict) # {'name': '张三', 'gender': '男', 'city': '北京'}
# 字典长度
print(len(my_dict)) # 3
# 字典键值对
print(my_dict.items()) # dict_items([('name', '张三'), ('gender', '男'), ('city', '北京')])
# 字典键
print(my_dict.keys()) # dict_keys(['name', 'gender', 'city'])
# 字典值
print(my_dict.values()) # dict_values(['张三', '男', '北京'])a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
f = dict({'one': 1, 'three': 3}, two=2)
print(a == b == c == d == e == f) # TrueTIP
字典的key和value可以是任何数据类型(key不可为字典)
嵌套字典:
student_sorce = {
'张三': {'语文': 80, '数学': 90, '英语': 85},
'王五': {'语文': 90, '数学': 85, '英语': 80}
}
student_sorce['张三']['语文'] # 80字典的遍历:
# 遍历字典的键值对
for key, value in student_sorce.items():
print(key, value)
# 遍历字典的键
for key in student_sorce:
print(key)
for key in student_sorce.keys():
print(key)
# 遍历字典的值
for value in student_sorce.values():
print(value)字典小案例:
empoyee_info = {
"王力宏": {
"apartment": "科技部",
"salary": 3000,
'level': 1
},
"李小龙": {
"apartment": "市场部",
"salary": 4000,
"level": 1
}
}
for key, value in empoyee_info.items():
if value['level'] == 1:
value['salary'] += 1000
value['level'] += 1
print(key, value)数据容器的总结
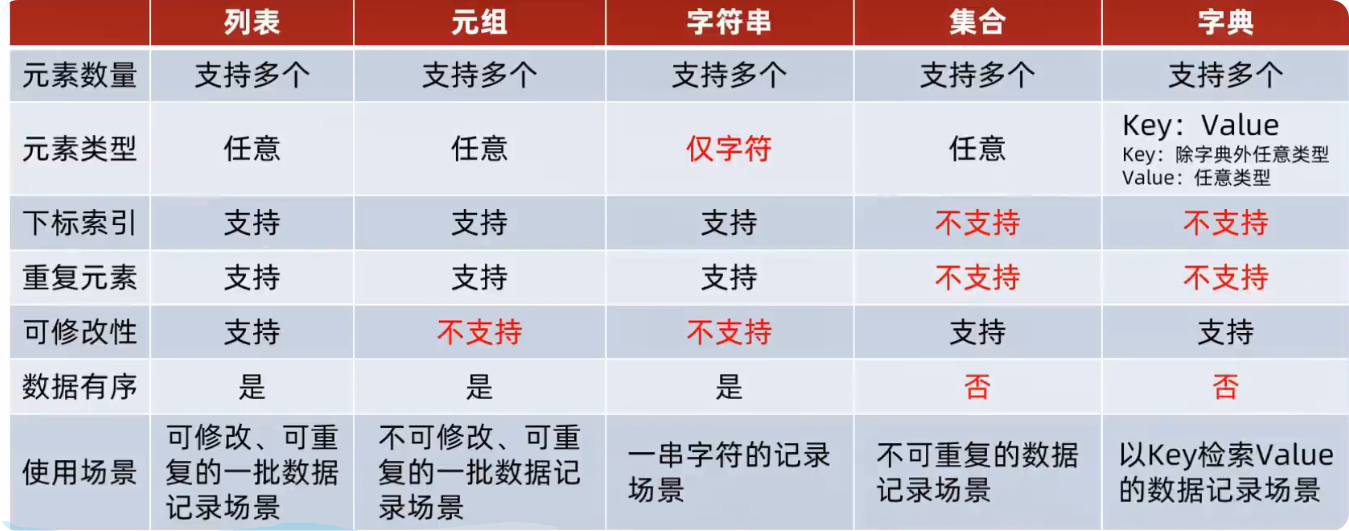
- 是否支持下标索引
- 列表:支持
- 元组:支持
- 字符串:支持
- 集合:不支持
- 字典:不支持
- 是否支持重复元素
- 列表:支持
- 元组:支持
- 字符串:支持
- 集合:不支持
- 字典:不支持
- 是否可以修改
- 列表:支持
- 元组:不支持
- 字符串:不支持
- 集合:支持
- 字典:支持
共同点
5类数据容器都支持for循环遍历
列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
尽管遍历的形式各有不同,但是,它们都支持遍历操作

通用功能:
| 功能 | 描述 |
|---|---|
| 通用for循环 | 遍历容器(字典是遍历key) |
| max | 容器内最大元素 |
| min | 容器内最小元素 |
| sum | 容器内元素的和 |
| len | 容器内元素的个数 |
| sorted | 对容器内元素排序 |
| count | 容器内某个元素出现的次数 |
| list | 转换为列表 |
| tuple | 转换为元组 |
| str | 转换为字符串 |
| set | 转换为集合 |
| dict | 转换为字典 |
| any | 判断容器内是否有元素 |
| all | 判断容器内是否全部元素为True |
| enumerate | 返回索引和元素 |
| zip | 将多个容器内元素打包成元组 |
| reversed | 反转容器 |
拓展字符串比较
在程序中,字符串所用的所有字符如:大小写英文单词,数字,特殊符号(!、\、|、@、#、空格等) 都有其对应的ASCI川码表值
每一个字符都能对应上一个:数字的码值
字符串进行比较就是基于数字的码值大小进行比较的。
字符串是按位比较,也就是一位位进行对比,只要有一位大,那么整体就大。
举例:
print('abc' < 'abd') # 一位位的进行比较
print('a' < 'ab')
print('a' > 'A')文件
编码
编码是指将计算机能理解的语言转换为机器能理解的语言的过程。
- ASCII编码:ASCII编码是最早的编码方式,它是基于拉丁字母表的,共有128个字符编码,其中32-126为可显示字符,0-31为控制字符。
- UTF-8 通用字符集编码:UTF-8编码是一种变长编码方式,它可以表示Unicode标准中的任何字符。UTF-8编码使用1-6个字节来表示一个字符,根据字符的不同,使用1-6个字节表示。
- GBK
- GB2312
- Big5
读取
文件的基本操作:
- 打开文件:
file_object = open(file_name, mode)- file_object: 打开的文件对象,是python的一种特殊类型,拥有属性和方法。
- 读取文件:
file_object.read([size])size参数可选,表示读取的字节数,如果省略或为负数则读取全部内容,读取并返回最多 size 个字符(文本模式)或 size 个字节(二进制模式) - 关闭文件:
file_object.close()
open(name,mode,encoding)函数的mode参数:
- name: 文件名(包含路径)
- mode: 打开模式,可选参数,默认值是r,表示只读模式,'w'表示写模式,'a'表示追加模式,'r+'表示读写模式,'w+'表示读写模式,'a+'表示读写模式。
- encoding: 编码格式,可选参数,默认值是None,表示系统默认编码。

f = open("input.txt", "r",encoding="utf-8")
# 方法1
for line in f:
print(line) # 逐行读取文件内容
# 方法2
print(f.readline()) # 读取一行
print(f.readline()) # 读取下一行
f.close() # 关闭文件 释放资源with语句
with 语句被用于异常处理上下文,它使得代码更加简洁,并自动处理资源的打开和关闭操作,这种模式被称为上下文管理器。它常用于文件操作,以确保文件在使用后正确地关闭,即便发生异常也能保证执行关闭操作。
基础语法:
with expression as variable:
# do something with variable当执行 with 语句时,会首先执行 expression 部分并调用对象的 _enter_ 方法。_enter_ 方法的返回值将赋给 variable。然后执行语句块内的代码。无论语句块执行过程中是否发生异常,都会执行对象的 _exit_ 方法。
使用 with 语句可以让我们不必显式调用 close() 来关闭文件,减少了编码的复杂性,并且使代码更加安全。
with open("input.txt", "r",encoding="utf-8") as file:
for line in file:
print(line) # 逐行读取文件内容写入
提示:
- 直接调用
write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区 - 当调用
flush方法的时候,内容会真正写入文件 - 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
import time
f = open("input.txt", "w", encoding="utf-8")
f.write('Hello World') # 加入缓冲区
f.flush() # 刷新缓冲区 写入咯
f.close() # 写入文件->关闭文件->释放资源
time.sleep(500000)追加
提示:
- 追加模式下,如果文件不存在,则会自动创建文件
- 追加模式下,如果文件存在,则会在文件末尾追加内容
- 追加模式下,如果文件已打开,则会在打开文件后,指针指向文件末尾
- 追加模式下,如果文件已关闭,则会报错
f = open("input.txt", "a", encoding="utf-8")
f.write('Hello World') # 追加内容
f.close() # 关闭文件->释放资源综合案例
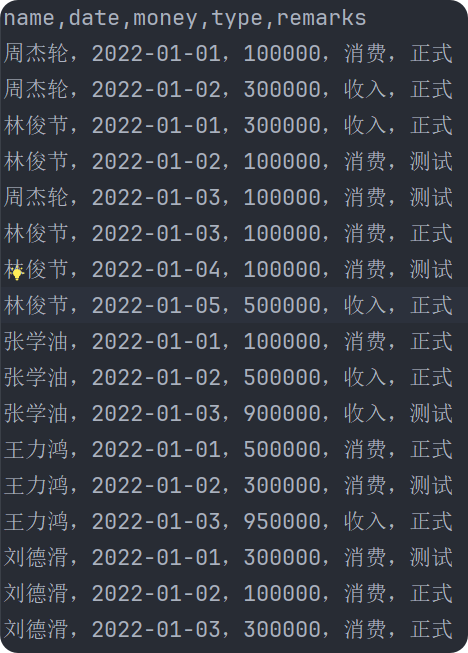
去除包含“测试”的行,并将其写入output.txt文件中:
with = open('input.txt', 'r', encoding='utf-8') as file:
for line in file:
if line.split(',')[-1].strip() != '测试':
with open('output.txt', 'a+', encoding='utf-8') as output_file:
output_file.write(line)异常
异常是程序运行过程中发生的错误,它会导致程序终止运行,并向用户显示错误信息。bug小虫子
处理异常
IMPORTANT
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
- 整个程序因为一个BUG停止运行
- 对BUG进行提醒,整个程序继续运行
try-except语句:
try:
# 可能发生异常的代码
except ExceptionName as e: # 捕获异常的类型
# 异常处理代码
else: # 异常没有发生
# 正常处理代码
finally: # 不管是否发生异常都会执行
# 释放资源的代码捕获全部异常:
try:
# 可能发生异常的代码
except: # 捕获全部异常
except Exception: # 捕获全部异常
# 异常处理代码as关键字
主要是在三个上下文中使用:
- 模块导入的时候,用
as关键字给模块指定别名 - 异常处理的在
try/except结构中,as关键字用于获取异常的是实例。 - 在一个
with上下文管理器中,as关键字用于指定一个变量名以存储with语句所管理的资源
异常的传递
异常是可以传递的,如果一个函数调用另一个函数,如果该函数发生异常,则会向上抛出,直到被捕获或者处理。
def func1():
try:
func2()
except Exception as e:
print(e)
def func2():
raise Exception("异常信息")
func1() # 输出:异常信息python模块
模块(Module)是python代码的基本单位,一个模块可以包含多个函数、类、变量等。
语法:
[from 模块名] import [模块|类|函数|变量|*] [as 别名]
from 模块名:导入模块,可以指定模块名,也可以使用*导入模块中的所有内容。import 模块|类|函数|变量:导入模块中的指定内容,可以使用逗号分隔多个内容。as 别名:给导入的模块、类、函数、变量指定别名。
import math
import math as m
from math import pi, sqrt as s
from math import *注意
不能同时使用 * 和 as 关键字
自定义模块
自定义模块就是将一些功能封装成一个模块,可以被其他程序调用。
注意
如果同时导入不同模块的同名功能,则会发生冲突,需要使用as关键字给功能指定别名。后面会覆盖前面的功能。
import calc # 导入模块
from calc import add # 导入模块中的函数
print(calc.__name__) # 输出:calc 就不是main了所以calc模块里面的调用就不会执行
if __name__ == '__main__':
print(add(1, 2)) # 3def add(*args):
total = 0
for i in args:
totla += i
return total
if __name__ == '__main__':
add(1, 2) # 3
# return sum(args)__name__
__main__模块:模块的入口,当模块被直接运行时,__name__变量的值为__main__。- 如果这个文件是被另一个Python文件导入的,那么
__name__将会是那个导入的文件的名字。
if __name__ == '__main__': # 判断当前的Python文件是被执行还是被导入为模块使用。
# 程序主体代码
pass__all__
模块的__all__变量是一个列表,用于指定模块中哪些成员可以被直接导入,其他成员只能通过模块名.成员名的方式导入。 类似于private关键字。暴露哪些成员给外界使用,哪些成员是私有的,哪些成员是内部的 import * 下使用。
from calc import * # 导入模块中的所有成员
__all__ = ['add'] # 指定模块中哪些成员可以被直接导入python包
我们知道,包可以包含一堆的Python模块,而每个模块又内含许多的功能。所以,我们可以认为:一个包,就是一堆同类型功能的集合体。
自定义包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__·py文件,该文件夹可用于包含多个模块文件从逻辑上看,包的本质依然是模块
文件夹结构:
my_package/
__init__.py # 包的初始化文件 必须存在,不然python会认为该文件夹不是一个包
module1.py
module2.py
...导入包:
import my_package.module1 as m1
import my_package.module2
m1.func1()
my_package.module2.func2()
from my_package import module1 as m1
from my_package.module2 import add__all__ 写到__init__.py(包的初始化文件管理)中,可以控制哪些成员可以被直接导入,其他成员只能通过模块名.成员名的方式导入。
第三方包
- pip:python安装包管理工具,可以安装第三方包。
- 包管理器:pip、conda、easy_install等。
- 包索引:pypi、conda、清华源等。
pip install [包名]:安装包
pip list:查看已安装的包
pip show [包名]:查看包的详细信息
pip uninstall [包名]:卸载包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称 指定源安装包
异常-模块-包 案例

📁my_utils/
🐍__init__.py
🐍file_util.py
🐍str_util.py
🐍main.py"""
文件处理相关的工具
"""
def print_file_info(file_name:str):
"""
打印文件信息
:param file_name:传入文件的路径
:return: None
"""
f = None
try:
f = open(file_name, 'r', encoding='utf-8')
print(f.read())
except FileNotFoundError as e:
print(e)
finally:
if f:
f.close()
def append_to_file(filename:str, data:str):
"""
向文件中追加数据
:param filename: 文件路径
:param data: 传入数据
:return: None
"""
with open(filename, 'a+',encoding='utf-8') as f:
f.write(data + '\n')
if __name__ == '__main__':
print_file_info('test.txt')from my_utils.str_util import substr
from my_utils.file_util import print_file_info, append_to_file
print(substr("Hello World", 0, 5))"""
字符串相关的工具模块
"""
def str_reverse(s:str):
"""
字符串反转
:param s: string
:return: string
"""
return s[::-1]
def substr(s:str,start:int,end:int,step=1):
"""
获取子字符串
:param s:string 原字符串
:param start:int,子字符串的起始位置
:param end:int,子字符串的结束位置
:param step:int,步长
:return: string
"""
return s[start:end:step]
if __name__ == '__main__':
print(str_reverse("hello"))
print(substr("hello world", 0, 5))